Going beyond GANs and capturing the diversity of the true data distribution
Generating High Fidelity Images With Subscale Pixel Networks And Multidimensional Upscaling is a powerful autoregressive method that is able to generate realistic images. This paper was presented and discussed in an AISC session led by Reza Fazeli. The details of the event can be found on the AISC website, and the Youtube video of the session can be found here. This article, written by Reza, was originally posted on Towards Data Science (TDS), and has been re-posted with both the permission of the author and the manager of TDS.
 Figure 1. High-resolution (256x256 pixels) 8-bit celebrity images generated using a deep autoregressive model trained on the CelebA-HQ dataset.
Figure 1. High-resolution (256x256 pixels) 8-bit celebrity images generated using a deep autoregressive model trained on the CelebA-HQ dataset.
Introduction
The celebrity faces in Figure 1 do not exist. They were generated using a deep autoregressive model introduced by researchers at Google Deepmind and Google Brain in a paper titled “Generating High Fidelity Images With Subscale Pixel Networks And Multidimensional Upscaling”. This work is particularly important as it takes a large step towards generating high-resolution, high-fidelity natural images while supporting the entire data distribution and guaranteeing the model’s ability to generalize. Don’t worry about the unfamiliar terminology introduced here. In this article, I will walk you through the paper and will explain all the terminologies.
Before we deep dive into the paper, let me give an overview of what we aim to cover here:
-
An overview of the paper: its goals and contributions;
-
A comparison of deep generative models for image generation and recent trends in this area;
-
An overview of deep autoregressive models for image generation: what they are, why we are interested in them, and major challenges of previous approaches; and
-
Deep dive into subscale pixel networks and multiscale upscaling: what they are, why they work, and how they compare against previous deep autoregressive models.
The goal of this paper is to build a deep autoregressive (AR) decoder that can unconditionally generate high-fidelity images. Fidelity refers to the degree to which a model generates real-looking images, and this work is able to generate highly realistic images at high resolutions using a deep AR model. We will discuss the main challenges associated with generating high-resolution, high-fidelity images using deep AR models and we will explain the solutions introduced in this work for resolving these issues.
Deep AR models such as pixelRNN and pixelCNN, which will be briefly introduced here, are examples of successfully using deep AR models for image generation; however, they are only able to generate relatively low-resolution images (32x32 and 64x64 pixel images). Generating high-resolution images with deep AR models is challenging as the size of the network increases linearly with the image size which is not sustainable. This paper, however, generates images of up to size 256x256 and the size of the network is not dependent on the image size. They generate 256x256 celebrity faces using a model trained on the popular CelebA-HQ dataset. They also generate 32x32 to 256x256 images of various categories using a model trained on the famous ImageNet dataset.
Deep Generative Models of Images
Generative models aim to learn the empirical distribution of the training data and generate images by sampling the learnt distribution with a trade-off between sample quality and sample diversity. Deep generative models of images can be divided into three main categories:
-
Variational Autoencoders (VAEs),
-
Generative Adversarial Network (GANs), and
-
Autoregressive (AR) Models.
Variational inference models (various types of variational autoencoders) approximate a latent space and generate a diverse set of images by sampling the learnt latent space; however, the generated images tend to be blurry. Adversarial image generation models (various types of generative adversarial networks) generate sharp, high-resolution images; however, there is no guarantee for these models to learn the entire data distribution in a meaningful way, and generated sample may not cover the entire data distribution. Finally, autoregressive models capture the entire data distribution guaranteeing a diverse set of generated samples; however, AR models tend to be limited to low-resolution images since memory and computation requirements grow with the size of the image. This is a problem that this paper attempts to resolve.
Other points to consider when comparing these modes are their training process and sampling efficiently, i.e. ability to rapidly generate new samples. Variational inference and adversarial models are relatively efficient at sampling time; however, this is an open area of research for autoregressive models as they tend to be inefficient during sampling. AR methods are simple models with a stable training process while adversarial methods are usually unstable during training and difficult to train.
Recent Trends in Deep Generative Modeling of Images
Google Deepmind researchers have recently published a number of ground-breaking research papers all focusing on deep generative models of images (see Figure 2). The central theme of these papers is that it is possible to generate high-fidelity and high-resolution samples without suffering from GAN’s shortcomings like mode collapse and lack of diversity. These results are very substantial as they show the value in exploring methods other than GANs, such as variational inference methods and autoregressive methods for image generation tasks. They also introduce a new metric for measuring how well a model has learned the data distribution. The idea is that if a model has learned the entire data distribution then its generated samples could be successfully used in downstream tasks like classification. They show that adversarial methods achieve lower scores than variational inference and autoregressive models showing that adversarial methods don’t necessarily learn the entire data distribution although they are able to generate high-fidelity images. This paper successfully uses autoregressive models to generate high-resolution, high-fidelity images while guaranteeing to learn the entire data distribution.
 Figure 2. Recent papers published by researchers at Google Deepmind with a common theme.
Figure 2. Recent papers published by researchers at Google Deepmind with a common theme.
Autoregressive Models
AR models treat an image as a sequence of pixels and represent its probability as the product of the conditional probabilities of all pixels. As shown in the equation below the probability of each pixel intensity is conditioned on all previously generated pixels.
In other words, to generate pixel xi in Figure 3, we need the intensity values of all previously generated pixels shown in blue.
![]() Figure 3. Generating individual image pixels using an autoregressive model
Figure 3. Generating individual image pixels using an autoregressive model
One of the challenges with adversarial models is that there is no intrinsic measure of generalization. Different metrics have been proposed in the literature with no consensus around a single metric making it challenging to compare the performance of different image generation models. On the other hand, AR models are forced by their objective function to capture the entire data distribution. They are likelihood-based models and are trained by maximum likelihood estimation. This allows for direct calculation of negative log-likelihood (NLL) scores which is a measure of the model’s ability to generalize well on held-out data and can be used as a proxy to measure the visual fidelity of generated samples. A successful generative model produces high-fidelity samples and it generalizes well on held-out data. While adversarial methods produce high-fidelity images, there’s no guarantee to capture the entire data distribution.
Previous Attempts
There have been a number of efforts in the past years to use deep AR models to sequentially predict the pixels in an image. Most notable models are PixelRNN and PixelCNN. PixelRNN uses LSTM layers to capture the information from previously generated pixels, whereas PixelCNN uses masked convolutions on previously generated pixels. A more recent Gated PixelCNNarchitecture combines ideas from pixelRNN and pixelCNN by using masked convolutions with LSTM gates, achieving performances comparable to PixelRNN while training as fast as PixelCNN. Most recently the PixelSNAILarchitecture has combined masked convolutions and self-attention, leveraging convolution’s high bandwidth access over a finite context size, and self-attention’s access over an infinitely large context to generate images. The baseline decoder in the paper described in this post uses an architecture similar to PixelSNAIL.
Despite these efforts, AR models have yet to generate high-resolution samples and capture the long-range structure and semantic coherence. Furthermore, as AR models are forced to support the entire data distribution, they tend to devote capacity to parts of the distribution irrelevant to fidelity.
Subscale Pixel Networks
The paper described in this post aims to generate high-resolution, high-fidelity images that capture details as well as global coherence by introducing Subscale Pixel Networks (SPNs) as well as an alternative ordering that divides a large image into a sequence of equally sized slices. The image slices are subsampled at every n pixels from the original image as shown in Figure 4. This architecture, decouples model size from image resolution/size, hence keeping memory and computation requirements constant. It also makes it easy to compactly encode long-range dependencies across the many pixels in large images.
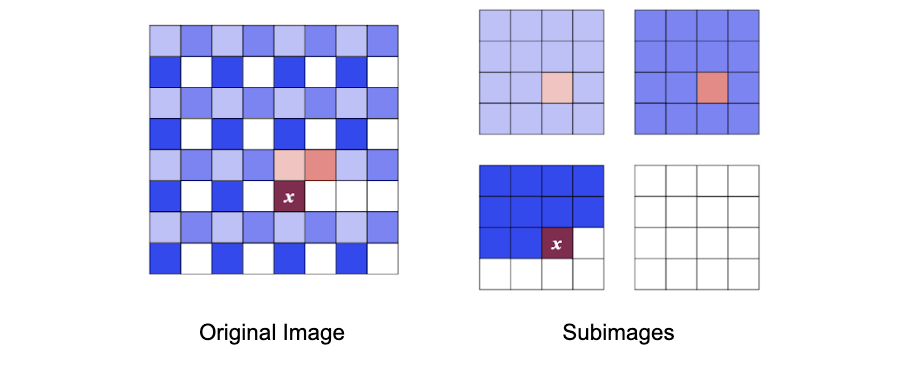 Figure 4. Subsampling 4 image slices from the original image
Figure 4. Subsampling 4 image slices from the original image
An SPN is a conditional decoder that generates images as a sequence of sub-images of equal size. These sub-images are then grown in size and depth to generate full-resolution, full-depth images in a process called Multidimensional Upscaling. This process is shown in Figure 5 and can be described as guiding the model to focus first on visually more salient bits of the distribution and later on visually less salient bits. The paper identifies two visually salient subsets: size and depth. Size refers to generating an initial slice (sub-image) then upsampling to the original image by generating one slice at a time conditioned on previously generated slices in a way that encodes a rich spatial structure. Depth refers to distinct networks for separately generating the most and least significant bits of each RGB channel.
 Figure 5. Three networks working together to generate the final full-size full-depth image
Figure 5. Three networks working together to generate the final full-size full-depth image
Therefore, 3 separate networks with similar architectures are trained:
a) a decoder trained on the small-size, low-depth image slices;
b) a size-upscaling decoder that generates the large-size, low depth-image conditioned on the initial image slice, i.e. the small-size, low-depth image; and
c) a depth-upscaling decoder that generates the large-size, high-depth image conditioned on the large-size, low-depth image.
Figure 6 (i) shows networks (a) and (b) working together to generate a full-size, low-depth image, while Figure 6 (ii) shows all three networks used to generate a large-size, high-depth image. The initial small-size, low-depth image slice (white pixels) is generated using network (a). Then network (b) is used to generate the large-size, low-depth image by generating the blue pixels. Finally, network (c) is used to generate the purple pixels which represent the remaining bits of each RGB channel of the large-size image.
![]() Figure 6. Distinct colors correspond to distinct neural networks used to generates various pixels of an image
Figure 6. Distinct colors correspond to distinct neural networks used to generates various pixels of an image
The SPN architecture is shown in Figure 7. The network has an encoder or slice embedder and a masked decoder. The encoder takes as input previously generated slices concatenated along the depth dimension and encodes the context of preceding slices in a single slice-shaped tensor. This embedding is passed to the decoder that uses masked convolutions and self-attention layers to generate image slices.
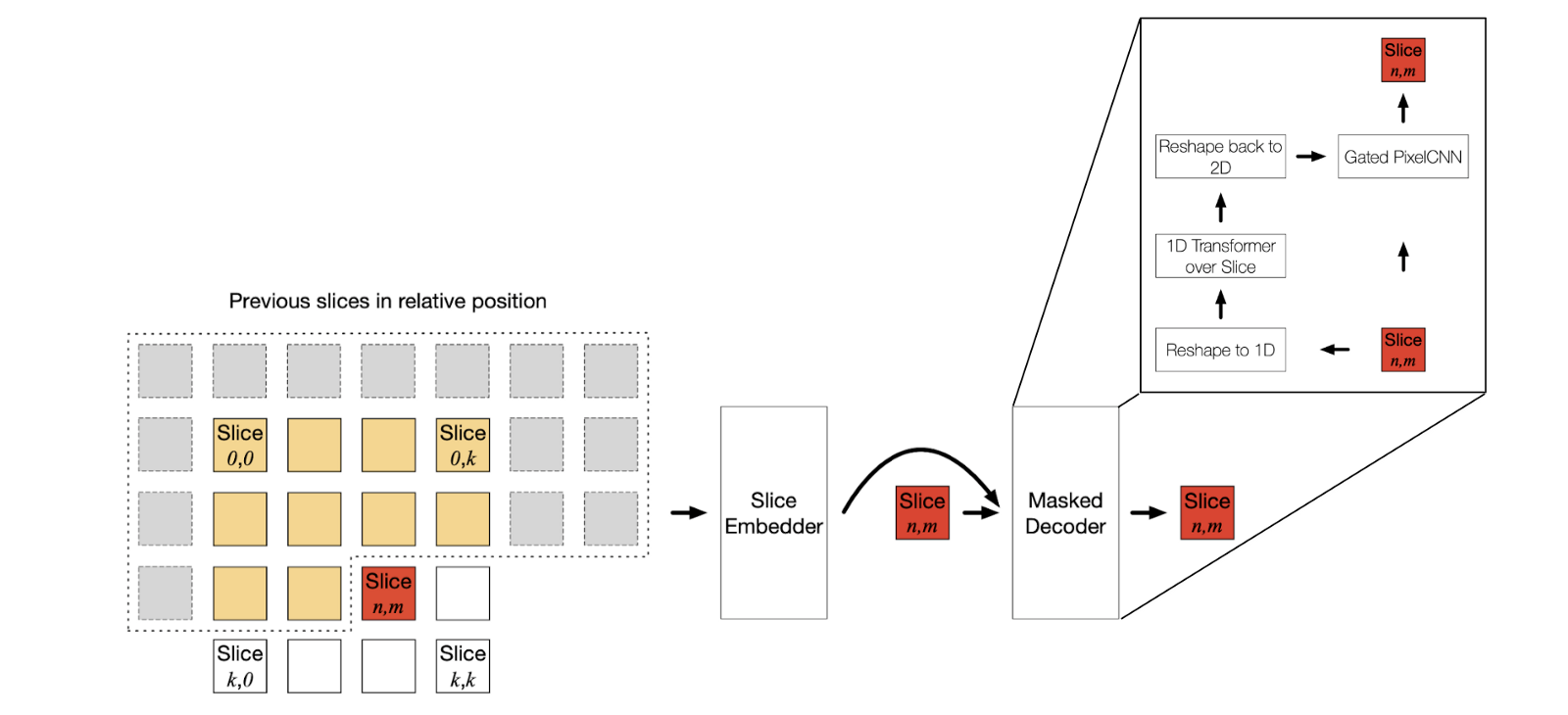 Figure 7. Subscale pixel network architecture
Figure 7. Subscale pixel network architecture
You can watch the full presentation on YouTube for a detailed explanation of the SPN architecture and further discussions around the algorithm and results of this paper.
Conclusion
In this post, I introduced a novel deep AR architecture that is able to learn the distribution of complex domains such as celebrity images and generate high-fidelity samples from the resulting learnt distributions. The generated samples show an unprecedented amount of semantic coherence and exactness of details even at high resolutions which is impressive.
 Figure 8. High-resolution (128x128 pixels) 8-bit images generated using a deep autoregressive model trained on the ImageNet dataset.
Figure 8. High-resolution (128x128 pixels) 8-bit images generated using a deep autoregressive model trained on the ImageNet dataset.
This paper shows that it’s possible to learn the distribution of complex natural images and attain high sample resolution and fidelity. Obtaining an accurate representation of data that captures the entire data distribution is critical for generating a variety of high-resolution samples, and the ideas introduced in this paper are important steps in that direction. This is particularly important for us here at Looka as we aim to generate a variety of high-quality design assets which are crucial for creating great designs. Looka’s mission is to make great design accessible and delightful for everyone, and we use deep learning to create the experience of working with a graphics designer online. In particular, we’re using deep generative models like the one introduced in this paper to automatically generate awesome design assets such as unique fonts and symbols.
I hope you’ve enjoyed this post. Please feel free to reach out if you have further questions or comments.
I’m a data scientist at Looka where we use deep learning to make great design accessible and delightful for everyone. If you’re interested in working at the intersection of AI and design, have a look at our careers page.